Relationenmodell
Laut Definition ist eine relationale Datenbank eine digitale Datenbank, die zur elektronischen Datenverwaltung dient und auf einem tabellenbasierten relationalen Datenbankmodell beruht. Grundlage des Konzeptes relationaler Datenbanken ist die Relation. Sie stellt eine mathematische Beschreibung einer Tabelle dar. Operationen auf diesen Relationen werden durch die relationale Algebra bestimmt.
- ER-Modellierung wurde dafür geschaffen. ER heißt Entity Relationship.
- Damit erstellen wir ER-Diagramme.
Grundlegendes Konzept:
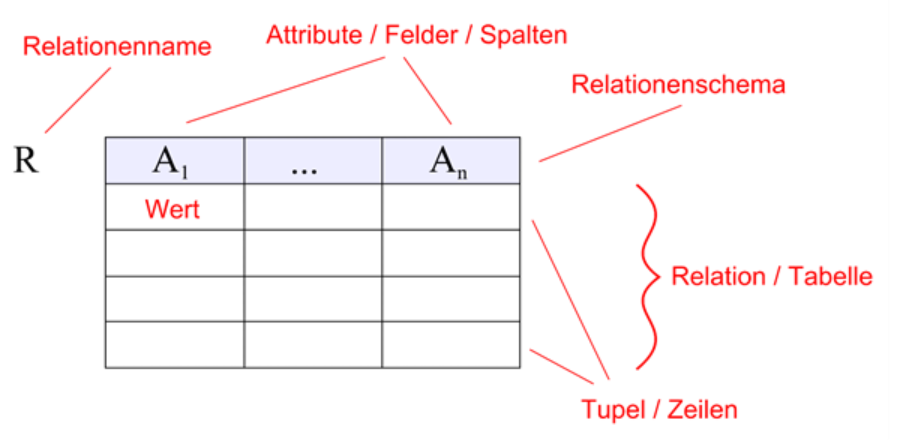
Eine relationale Datenbank kann man sich als eine Sammlung von Tabellen (den Relationen) vorstellen, in welchen Datensätze abgespeichert sind. Jede Zeile in einer Tabelle ist ein Datensatz und stellt in unserem Fall eine Entität dar. Jede Zeile besteht aus einer Reihe von Attributwerten (Attribute = Eigenschaften), den Spalten der Tabelle. Die Anzahl und der Typ der Attribute für eine Relation nennt man Relationenschema. Das Bild illustriert die Relation R mit Attributen A1 bis An in den Spalten.

In diesem Beispiel heißt die Relation Schüler und stellt somit den Entitätstypen dar.
Das Relationenschema besteht aus drei Attributen, die verschiedene Werttypen haben.
Schüler-ID ist der Primärschlüssel und daher als Attribut unterstrichen.
Jede Zeile stellt somit einen Schüler mit seinen Eigenschaften dar. Alle sind in der Relation ‘Schüler’.
Jetzt wissen wir in welcher Form eine relationale Datenbank die Relationen abspeichert. Diesen tabellarischen Zustand wollen wir nun erreichen. Das erstellte ER-Diagramm kann man nun in diese Tabellen umwandeln.
Transformation:
Eine relationale Datenbank kann man sich als eine Sammlung von Tabellen (den Relationen) vorstellen, in welchen Datensätze abgespeichert sind. Jede Zeile in einer Tabelle ist ein Datensatz und stellt in unserem Fall eine Entität dar. Jede Zeile besteht aus einer Reihe von Attributwerten (Attribute = Eigenschaften), den Spalten der Tabelle. Die Anzahl und der Typ der Attribute für eine Relation nennt man Relationenschema. Das Bild illustriert die Relation R mit Attributen A1 bis An in den Spalten.
- Jeder Entitätstyp wird als Tabelle dargestellt. Jede Tabelle benötigt einen Primärschlüssel.
- Jede n:m-Beziehung wird durch eine eigene Tabelle dargestellt.
- Jede 1:n- und 1:1-Beziehung mit eigenen Attributen wird wie bei Regel 2 durch eine eigene Tabelle dargestellt.
- Jede 1:n-Beziehung ohne eigene Attribute wird so dargestellt, dass der Primärschlüssel des 1-Entitätstyps Fremdschlüssel des n-Entitätstyps wird.
- Jede 1:1-Beziehung ohne eigene Attribute wird so dargestellt, dass der Primärschlüssel des ersten Entitätstyps beim zweiten Entitätstyp Primär- und Fremdschlüssel zugleich wird.
- Sind Regel 4 oder 5 nicht anwendbar, dann wird für die Beziehung eine gesonderte Tabelle angelegt.
Beispiel Transformation:
Jeder Entitätstyp ist eine eigene Tabelle mit einem Primärschlüssel. Optimalerweise ist der Primärschlüssel ein einzelnes Attribut. Im Zweifel wird ein künstlicher Primärschlüssel zugewiesen, wie z.B eine ID. Jede Zeile einer Tabelle ist eine Entität des Entitätstyps.
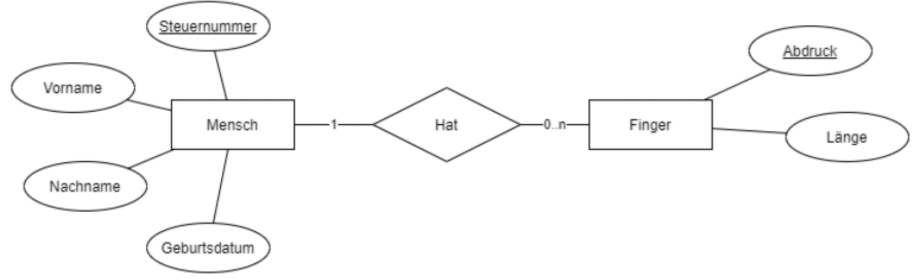
Relationen werden aufgeteilt. Dazu geht man je nach Kardinalität unterschiedlich vor
-


-
m:n-Kardinalitäten erfordern eine zusätzliche Tabelle für die Relation. (Das erstellen der Tabelle für die Entitätstypen (Hier: Schüler und Kurs) wurden schon in Regel 1 erklärt.) In der zusätzlichen Tabelle gibt es eine Spalte für jeden Primärschlüssel der beteiligten Entitätstypen. Primärschlüssel, die in einer „fremden“ Tabelle auftauchen, nennt man dort Fremdschlüssel.
In diesem Beispiel besucht Schüler Nr. 23 in realität zwei Kurse.
-
Jede 1:n- und 1:1-Beziehung mit eigenen Attributen wird wie bei Regel 2 durch eine eigene Tabelle dargestellt. Hätten diese beiden “Hat” Beziehungen Attribute, würde die Regel greifen, sonst nicht.
-
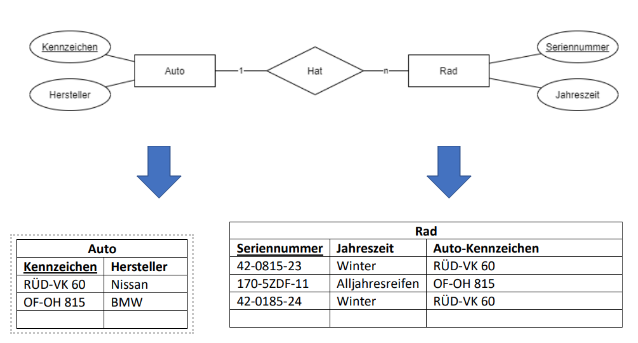
Bei 1:n-Kardinalitäten wird in die Tabelle der n-Kardinalität eine zusätzliche Spalte mit dem Primärschlüssel der 1-Kardinalität aufgenommen. Dies ist nun ein Fremdschlüssel in der zweiten Tabelle.
-
Bei 1:1-Kardinalitäten fasst man beide Entitätstabellen zu einer Tabelle zusammen oder der Primärschlüssel des ersten Entitätstyps wird beim zweiten Entitätstyp Primär- und Fremdschlüssel zugleich. (Möchte man das nicht, kann man wahlweise wie in Regel 2 oder 4 vorgehen.)
-
Sind Regel 4 und 5 nicht anwendbar, also in allen anderen Fällen (Auch bei Kardinalitäten mit 0...n) geht man wie in ERegel 2 vor und erstellt für die Relation eine neue Tabelle.